MLOps for Startups: Battle-tested Guide to Running LLMs in Production
Learn MLOps for startups with a practical guide to deploying, scaling, and maintaining LLMs in production. Improve reliability, speed, and operational efficiency.
Nov 12, 2025

MLOps isn't just a technical luxury for startups - it's essential for business success with Large Language Models (LLMs). The reality of deploying LLMs in production is nowhere near as simple as "plug and play." It needs a thorough, multi-faceted approach that weighs enormous potential against most important risks. We learned this lesson through experience.
One industry expert points to what they call "the Cheap Illusion" - a belief that LLM implementation costs only pennies per query. But without well-thought-out strategies like aggressive caching, tiered architectures, and model quantization, cloud bills can skyrocket to tens of thousands monthly. Good MLOps practices do more than control costs. They prevent inconsistent deployments, eliminate error-prone manual updates, and help maintain compliance. The deployment and management of models in production ultimately determines AI project success.
This piece shares our battle-tested MLOps best practices for machine learning deployment, with a focus on LLMs. We'll cover everything from building a lean LLMOps architecture to setting up effective model monitoring systems. Startups need these insights to make their AI initiatives work. Our LLM deployment guide will help you direct your path through production environments, whether you're beginning your ML experience or scaling existing systems.
Building a Lean LLMOps Stack for Startups
A well-laid-out MLOps stack is the foundation of successful LLM implementations. Startups with limited resources should focus on key components and avoid unnecessary complexity.
Choosing Between Open-Source and API-Based LLMs
Your first big decision in MLOps architecture is picking between open-source models like LLAMA-2 or proprietary API-based options such as OpenAI's GPT or Anthropic's Claude. This choice will affect your deployment approach by a lot.
Open-source models give you great advantages in data autonomy and privacy. The quality gap between self-hosted and API-based models has become smaller, and models like Vicuna now match more than 90% of ChatGPT quality. Most fine-tuned open-source models are 7B or 13B parameter versions that run on user-grade GPUs, which could save money for high-volume applications.
API-based models shine when it comes to development speed and simplicity. You won't need to worry about infrastructure setup, and they usually work with just a few lines of code. Companies like OpenAI's economies of scale make their services affordable at lower usage levels.
Decision framework: Start with APIs for most general applications while building local model capabilities as a backup. Privacy-sensitive tasks or specific, repeatable functions need open-source alternatives.
Using LangChain for Prompt Orchestration
LangChain has become a vital MLOps tool for startups building LLM applications. This open-source orchestration framework speeds up development by offering standard ways to connect components like LLMs, retrievers, and agents.
The framework stands out with its many integrations with popular providers and a standard approach to putting components together. Startups can quickly build autonomous applications with under 10 lines of code thanks to LangChain's pre-built agent architecture.
The framework might be more complex than direct API usage, but its modularity and abstractions are worth it for complex LLM applications that need context-awareness through data source connections.
Lightweight Vector Stores: FAISS vs Weaviate
Vector databases are now essential for retrieval-augmented generation (RAG) applications. FAISS and Weaviate offer different approaches for startups.
FAISS (Facebook AI Similarity Search) is great at similarity search functionality and uses advanced algorithms to optimize vector comparisons. It really shines with GPU acceleration, which makes search operations faster on large datasets.
Weaviate works as a complete vector database that combines object and vector storage for better indexing. You get built-in support for different media types and quick queries with low latency.
We used these specific requirements to pick the right solution for RAG applications. FAISS works best for maximum performance in similarity search operations, especially with large-scale datasets. Weaviate makes more sense if you need structured filtering alongside vector search functionality.
Want to build your lean LLMOps stack? Reach out to us at https://www.kumohq.co/contact-us for expert guidance on implementing these technologies in your startup.
Fine-Tuning and Adaptation with Limited Resources
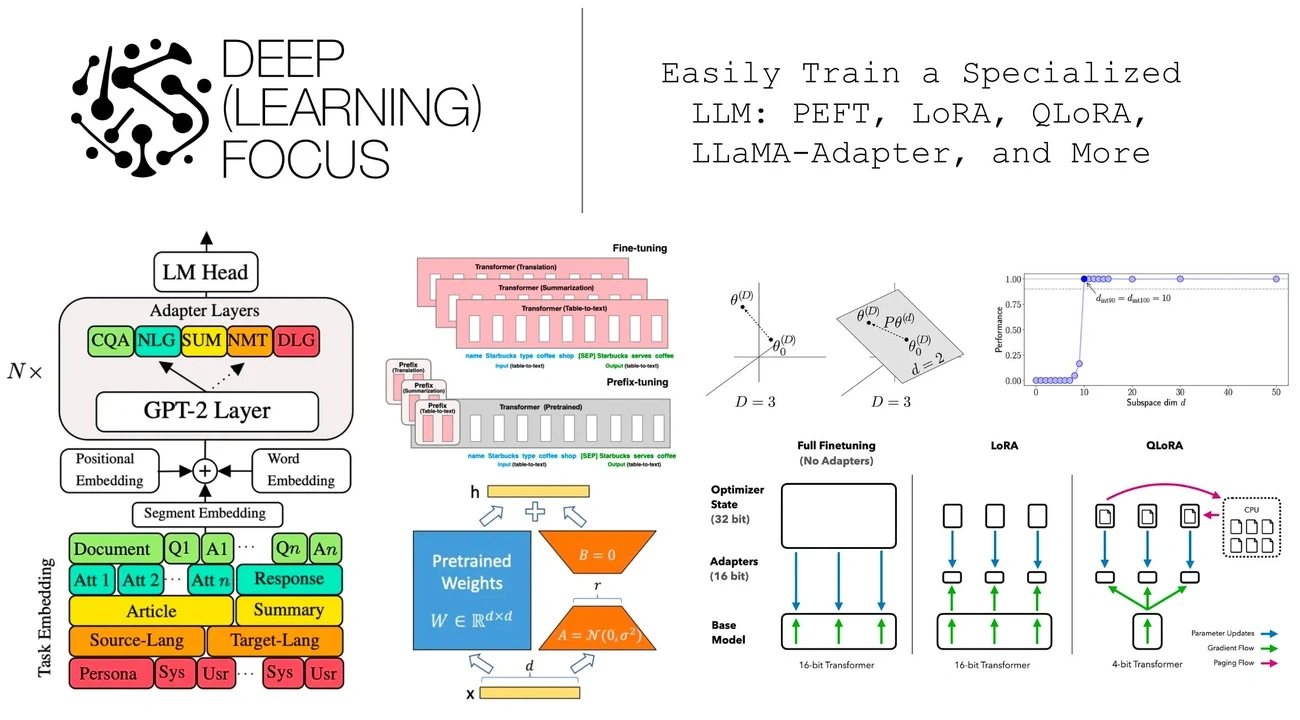
Image Source: Deep (Learning) Focus - Substack
Most startups find it too expensive to fine-tune large language models. Several techniques can help adapt these models without getting pricey or compromising on quality.
LoRA and PEFT for Parameter-Efficient Fine-Tuning
Resource-constrained teams can benefit from Parameter-efficient fine-tuning (PEFT). This breakthrough technique updates just 1-6% of parameters instead of all model weights. LoRA (Low-Rank Adaptation) stands out as an effective solution that introduces small trainable matrices into neural layers while keeping most weights frozen. QLoRA improves efficiency by loading pretrained models as quantized 4-bit weights instead of 8-bit, and it works just as well despite the compression. The cost savings are significant - a single QLoRA fine-tuning session costs only $13 on one GPU compared to $322 for traditional fine-tuning on 8 A100 GPUs.
Using Synthetic Data for Domain-Specific Tasks
High-quality training data often holds back LLM projects. Synthetic data generation provides a solution, especially when you have scarce, sensitive, or expensive-to-collect information. Larger models (teachers) typically generate training data for smaller models (students) in this approach. Synthetic data generation does more than just expand datasets - it helps protect privacy, allows safe testing before deployment, and lets teams explore new scenarios without expensive ground data collection.
Training Small Expert Models with GPT-4 as Teacher
Knowledge distillation gives startups another powerful option. Small models taught by larger ones can sometimes perform better than their teachers - a 770M parameter model surpassed a 540B model on certain tasks. The TinyStories project shows this approach in action. GPT-4 generated children's stories that trained small models with as few as 30M parameters. These specialized small models achieved impressive results despite being thousands of times smaller than their teachers. This makes them perfect for budget-friendly production deployments.
Evaluation, Testing, and Monitoring in LLMOps
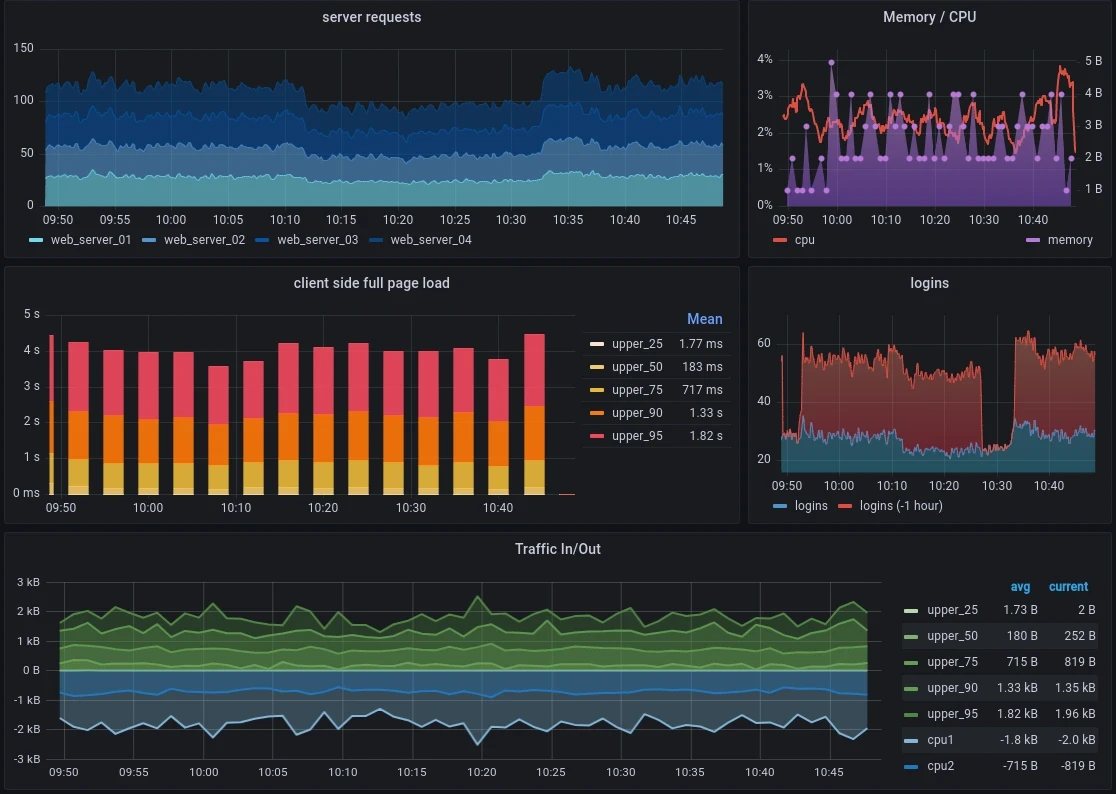
Image Source: Grafana
LLMOps implementations need strong evaluation and monitoring systems to succeed. Models can become unreliable in production without proper validation mechanisms, no matter how well-designed they are.
Human-in-the-Loop Evaluation with SuperAnnotate
LLM evaluation needs human expertise and automated systems working together. SuperAnnotate's structured human feedback throughout the model's lifecycle focuses expert attention where it matters most. The process works in three main phases: data labeling, quality assessment, and error correction. Teams can balance cost with coverage by sampling 1-5% of outputs in production environments. This helps catch ambiguous or new failure modes.
Tracking Prompt-Level Failure Patterns
Teams can prevent recurring issues by spotting patterns in LLM failures. Detailed observability answers vital questions about model performance. The model's hallucination patterns, user queries, and response quality consistency become clear. Teams can cluster similar failures, understand why it happens, and make targeted improvements by tracking prompts, responses, and evaluation scores.
Latency and Cost Monitoring with Prometheus + Grafana
Prometheus and Grafana are the foundations of LLM monitoring pipelines. These tools track essential metrics efficiently. Request frequency helps manage usage, response times show efficiency, and token usage controls costs. Teams can find bottlenecks across their LLM application flow through OpenTelemetry integration and distributed tracing.
Shadow Mode Testing for New Model Versions
Shadow testing runs candidate models next to production systems without showing their outputs to users. The new version gets real traffic and collects responses to compare, which helps catch issues that offline testing might miss. Teams can build confidence in new models before promotion, and this substantially reduces deployment risks.
Governance, Security, and Compliance for LLMs
Security considerations are the foundations of protecting LLM implementations throughout their lifecycle. Good governance turns theoretical security into practical processes.
Prompt Versioning and Audit Trails
Healthcare, finance, and legal services need complete audit trails to document system behavior. A good prompt versioning system creates unchangeable records of the text the model received. It tracks when changes happened and who approved them. We can call it "git for prompts" that helps with compliance reviews and investigations. The system also lets us roll back changes when needed.
Access Control for Sensitive Data in Prompts
Role-based access control (RBAC) is a basic security requirement that limits who can use LLMs and what they can do. This protection reduces the risks from injection attacks and ensures only approved staff can work with sensitive data. Organizations must use multi-factor authentication. They need to keep detailed logs of access attempts and encrypt model data and outputs to stop information leaks.
GDPR and HIPAA Considerations in LLM Workflows
Organizations using LLMs must guide through complex regulations with heavy penalties. GDPR violations can cost up to €20 million or 4% of global turnover. HIPAA violations can lead to fines of $1.5 million each. GDPR focuses on individual consent and autonomy. It requires lawful processing, minimal data use, and protection of subject rights. HIPAA centers on institutional control and needs administrative, physical, and technical safeguards to protect health information.
Conclusion
This piece explores how good MLOps practices build the foundation for successful LLM implementations in startup environments. Your experience from picking the right models to meeting regulatory rules needs careful planning and smart use of resources. Startups should find the right balance between their technical abilities and business limits in the digital world of model deployment.
Smart architecture decisions kick off a good LLM implementation. You can choose between open-source models like LLAMA-2 for privacy and control or API-based services like OpenAI for speed and simplicity. On top of that, tools like LangChain make development easier. Vector databases help create powerful retrieval-based generation apps that improve model outputs by a lot.
Limited resources shouldn't stop startups from creating specialized models. Teams can adapt large models at a fraction of usual costs with parameter-efficient fine-tuning techniques like LoRA and PEFT. Small teams can build powerful domain-specific apps through synthetic data generation and knowledge distillation.
Reliable evaluation systems play a key role in production success. Teams can spot problems before they affect users through human-in-the-loop validation, failure pattern tracking, and detailed performance monitoring. Shadow testing adds extra safety layers when rolling out new model versions and reduces possible disruptions.
Security and compliance must form the base of all LLM implementations, especially in regulated industries. Good governance frameworks protect businesses and their users from potential risks through prompt versioning, access controls, and regulatory awareness.
The road to successful LLM deployment has its challenges. Yet startups that follow these practices can achieve great results with modest resources. You can get expert help to apply these LLMOps practices in your startup. Reach out at https://www.kumohq.co/contact-us for guidance that fits your specific use case and industry.
Note that good MLOps isn't just about technical excellence. It gives your startup a strategic edge to distinguish itself in AI-driven markets. While the work needs attention to detail, forward-thinking teams find the competitive benefits worth their investment.
FAQs
Q1. What is MLOps and why is it important for startups using LLMs? MLOps (Machine Learning Operations) is a set of practices for efficiently deploying and managing machine learning models in production. For startups using Large Language Models (LLMs), MLOps is crucial as it helps balance the immense potential of these models with significant risks, prevents inconsistent deployments, eliminates manual errors, and ensures compliance.
Q2. How can startups build a lean LLMOps stack? Startups can build a lean LLMOps stack by focusing on essential components like choosing between open-source and API-based LLMs, using LangChain for prompt orchestration, and implementing lightweight vector stores like FAISS or Weaviate. The choice depends on specific requirements such as data privacy, development speed, and scalability needs.
Q3. What are some efficient fine-tuning techniques for LLMs with limited resources? Efficient fine-tuning techniques for resource-constrained startups include Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA (Low-Rank Adaptation), using synthetic data for domain-specific tasks, and training small expert models with larger models like GPT-4 as teachers. These approaches allow for model adaptation without the need for extensive computational resources.
Q4. How can startups effectively monitor and evaluate LLMs in production? Startups can monitor and evaluate LLMs in production by implementing human-in-the-loop evaluation, tracking prompt-level failure patterns, using tools like Prometheus and Grafana for latency and cost monitoring, and employing shadow mode testing for new model versions. These practices help identify issues early and ensure consistent model performance.
Q5. What are the key governance and security considerations for LLM deployments? Key governance and security considerations for LLM deployments include implementing prompt versioning and audit trails, establishing access controls for sensitive data, and ensuring compliance with regulations like GDPR and HIPAA. These measures help protect user data, maintain traceability, and mitigate potential legal and security risks associated with LLM use.


