How to Build a Data Strategy for AI: From Raw Data to Production-Ready Assets
Learn how to create a strong data strategy for AI - from organizing raw data to building clean, production-ready assets that fuel accurate and scalable AI systems.
Nov 12, 2025

The global AI governance market will reach $16.5 billion by 2033, with a remarkable 25.5% CAGR from 2024 to 2033. This rapid growth shows how a strong data strategy for AI has become essential in today's digital world. Nearly all organizations (97%) plan to invest in generative AI within the next 1-2 years. Many companies still lack the foundation needed to make these investments work.
A solid data management strategy serves as the life-blood of using data as a strategic asset. The stakes couldn't be higher - organizations that use AI models trained on poor-quality data lose an average of $406 million in revenue each year. Companies without clear AI data governance frameworks face serious risks, from regulatory compliance issues to security problems.
This piece will show you how to build a complete data strategy for AI products that turns raw data into production-ready assets. You'll learn about governance foundations, expandable data pipelines for AI and effective data preparation methods. These best practices will help your AI initiatives thrive on quality data that creates business value while staying secure and compliant.
Establishing a Data Governance Foundation for AI
The foundation of successful AI data governance needs a well-laid-out approach that is different by a lot from traditional data management. Organizations must have a unified data and AI governance model to make use of AI's potential while managing its unique risks and complexities.
Defining Roles: Data Owners, Stewards, and Custodians
Effective AI data governance depends on a clear division of responsibilities. Data owners, who are senior leaders, take responsibility for data classification, protection, use, and quality. These leaders create governance policies and make key decisions. Data stewards act as subject matter experts who have deep knowledge of specific datasets and maintain their quality based on data owners' standards. Data custodians handle the technical infrastructure as they implement security controls and manage storage systems. This three-level structure will give a proper oversight without creating bottlenecks that don't deal very well with 73% of digital transformation initiatives.
Arranging Data Strategy with AI Product Goals
Data becomes a growth-driving asset instead of a passive byproduct when strategic goals come together. The most successful organizations combine two approaches. They build a compelling vision for data transformation while creating solid foundations and efficient operations. This balanced approach prevents both aimless system building and goal pursuit without proper data support. On top of that, a strong data foundation has governance policies that guide data quality, privacy, and security practices through architecture.
AI Data Governance Framework vs Traditional Governance
Traditional data governance can't meet AI's unique needs. To cite an instance, see these key differences:
- AI systems must have continuous monitoring for performance, ethical considerations, and dynamic decision-making as models evolve.
- New regulations like the EU AI Act require transparency and auditable processes that traditional frameworks can't support.
- Traditional governance stays static and policy-based, while AI governance must remain dynamic, continuous, and multidisciplinary.
Data Classification and Access Control Policies
AI-powered classification changes data management through automated organization based on set criteria. These systems grasp both context and intent as they tell sensitive information apart in different contexts. Effective access control makes sure the right people can access the right data at the right time while protecting sensitive information. A properly implemented data access governance helps teams spot and track sensitive data, understand user permissions, and keep clear audit trails.
Data Collection and Quality Standards for AI Systems
AI systems work best when they process high-quality, relevant data. The success of AI implementations depends on understanding different data types and setting up strict quality standards.
Data Collection for AI Systems: Structured vs Unstructured
Structured data has predefined formats in tables with rows and columns. Traditional analytics tools can process it easily. Database records, spreadsheets, and sensor data are good examples. Unstructured data works differently. It has no predefined formats and exists as text documents, images, videos, or audio files. AI needs extra processing to find patterns in this data. Research shows that approximately 80% of organizational data is unstructured, while only 20% is structured. These numbers substantially affect project complexity, timeline, and resource needs for AI initiatives.
Data Profiling and Validation Techniques
Data profiling, also known as data archeology, helps teams review and cleanse data to understand its structure and maintain quality standards. The process uses three main approaches. Structure discovery verifies format consistency. Content discovery looks at individual elements for quality issues. Relationship discovery finds connections between datasets. Teams use specific methods like column profiling to count value frequencies, cross-column profiling to analyze table dependencies, and cross-table profiling to study relationships between different tables.
Automated Data Quality Checks using AI
AI plays a crucial role in verifying data quality. Machine learning-based validation learns patterns of valid and invalid data points. It then predicts if new data is valid without human input. AI finds duplicates, standardizes formats, and spots anomalies faster than traditional methods. A study shows that 77% of IT decision-makers don't trust their organization's data quality, which makes AI-automated validation essential.
Metadata Management and Data Lineage Tracking
Metadata—"data about data"—gives vital context about origin, classification, sensitivity, transformations, access, and updates. Data lineage tracks data's path from creation to use. It records all changes and processes along the way. This tracking helps organizations verify accuracy, fix errors, understand data dependencies, and follow regulations.
Designing Scalable Data Architecture and Pipelines
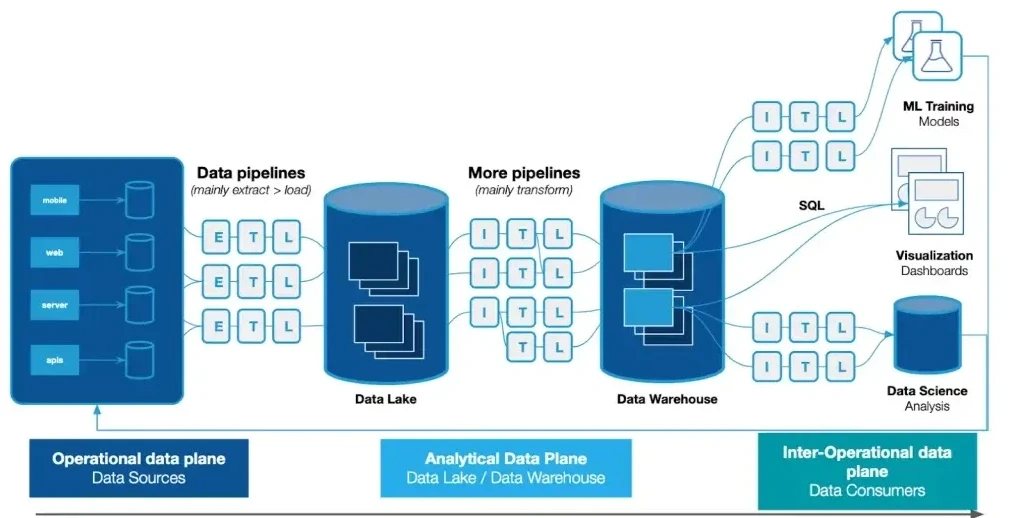
Image Source: Timeplus
Adaptable data architecture serves as the foundation that revolutionizes raw data into production-ready assets for AI systems. Building this infrastructure needs careful thought about storage options, processing pipelines, and maintenance strategies.
AI Data Architecture: Data Lakes vs Lakehouses
Data lakes emerged as a solution to manage the flood of big data in the early 2010s. These systems store data in its native format using a schema-on-read approach. Unlike traditional warehouses, lakes can store structured, unstructured, and semi-structured data at the same time. In spite of that, they don't perform well with queries.
Data lakehouses blend the best of both worlds and are a great way to get low-cost storage with warehouse-like analytics capabilities. On top of that, lakehouses use ACID transactions through transaction logs or table-level locks. This feature fixes a major weakness of traditional data lakes. The hybrid setup creates a unified platform that doesn't need separate systems for different workloads.
ETL/ELT Pipelines for Real-Time AI Workloads
Traditional ETL changes data before loading it into target systems. ELT takes a different approach - it loads raw data straight into the target warehouse first and transforms it later. This makes it faster and better suited for AI workloads.
Remote execution engine brings a breakthrough by splitting design time (control plane) from runtime (data plane). This creates ultimate deployment flexibility. Teams can run data pipelines closest to business data while keeping the benefits of a fully managed model. Organizations can design data pipelines once and run them anywhere.
Data Versioning and Reproducibility in ML Pipelines
Reproducibility lets teams duplicate experiments by tracking changes in code, data, and model hyperparameters. Organizations risk inconsistencies and errors without it, which hurts trust in AI systems.
Three common versioning approaches include:
- Data duplication: Making separate copies (impractical for large datasets)
- Metadata: Adding timestamps to schemas for time travel capabilities
- Full data version control: Building sustainable versioning as part of the native data environment
DVC helps organizations manage multiple versions of datasets and ML models. Teams can switch between workspace versions easily.
Cloud vs On-Premise Storage for AI Data Strategy
Several factors influence the choice between cloud and on-premise deployment:
Cloud storage brings flexibility, scalability, and affordability with pay-as-you-go models. Teams can experiment with emerging AI technologies without big upfront costs. Cloud platforms handle larger and more complex models thanks to their scalable infrastructure.
On-premise solutions give greater control, better security, and customization options. These systems need significant infrastructure investments and limit scalability.
Most organizations find that mixing cloud and local storage provides the best balance of speed and scale for AI workloads. Looking to design your hybrid architecture? Contact our experts for tailored guidance.
Monitoring and Alerting in Scalable Data Pipelines
Good monitoring tracks pipeline performance and health continuously. This ensures smooth data flow without interruptions or quality issues. Strong monitoring needs schema validation, logging, automated quality checks, and scalable observability infrastructure.
Immediate alerts tell teams about issues like data source failures or pipeline slowdowns quickly. This helps teams respond fast and reduce downtime. Anomaly detection spots unusual patterns before they become serious problems, which keeps data quality high throughout the pipeline.
Preparing Data for AI Model Training and Compliance
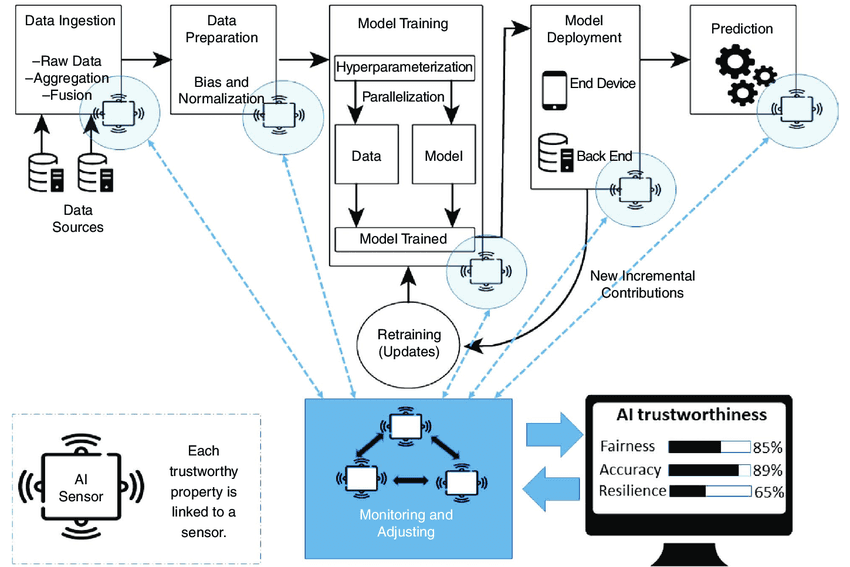
Image Source: ResearchGate
Raw data preparation for AI models needs careful attention to technical optimization and compliance requirements. This two-pronged approach will give a solid foundation for model performance while meeting privacy regulations.
AI Data Preparation Techniques: Feature Engineering and Labeling
Feature engineering turns raw data into formats that maximize model performance. This happens through selecting, creating, and extracting relevant features. The process substantially improves predictive accuracy by giving models the right information. Teams can create new features from existing data, fix invalid features, and reduce dimensionality through methods like Principal Components Analysis.
Data labeling is a vital step that adds meaningful context to raw data. This helps AI systems interpret information correctly. The human-in-the-loop process forms the foundations of supervised learning models. Teams can use internal labeling or crowdsourcing approaches to get this work done.
Data Anonymization and Masking for Privacy
Data anonymization helps protect individual identities while keeping data useful for AI training. Here are the main techniques:
- k-Anonymity: Makes each individual's information indistinguishable from at least k-1 others
- l-Diversity: Ensures anonymized groups contain diverse sensitive attributes
- t-Closeness: Maintains distribution of sensitive attributes within threshold limits
Differential privacy adds adjusted noise to datasets. This prevents individual data inference while preserving combined patterns for analysis.
AI Data Privacy and Compliance: GDPR, CCPA, HIPAA
Regulatory frameworks set specific requirements for AI data handling. GDPR requires organizations to implement documented protocols for personal data protection. These include consent management, breach notifications within 72 hours, and right-to-be-forgotten provisions. HIPAA protects health information through its Privacy Rule, Security Rule, and Breach Notification Rule. Fines range from $100 to $50,000 for the whole ordeal.
Data breach costs reached $4.88 million in 2024. This makes compliance both a regulatory and financial necessity.
Bias Detection and Fairness Audits in Training Data
AI bias happens when systems produce outcomes that unfairly discriminate against certain groups. Selection bias comes from non-representative training data. Measurement bias results from inaccurate variable measurement. Stereotyping bias reinforces harmful stereotypes.
Teams can fight bias by varying training datasets and using bias detection frameworks like IBM AI Fairness 360. Regular algorithmic audits also help. These steps ensure AI systems promote inclusivity instead of reinforcing societal prejudices.
Retention and Deletion Policies for AI Datasets
AI data retention policies control how long information stays stored, managed, and eventually deleted. Organizations should create dynamic, lifecycle-based policies that balance AI model training needs with regulatory demands instead of keeping everything forever.
Microsoft 365 Copilot's retention policies state that personal data shouldn't be kept longer than needed. Automated deletion workflows start after retention periods end. Need help creating compliant retention strategies? Contact our experts to learn about balancing AI training requirements with regulatory compliance.
Conclusion
A resilient data strategy serves as the life-blood of successful AI implementation in today's competitive business landscape. This article explores the key components needed to transform raw data into production-ready AI assets.
Clear data governance creates the framework needed for AI success. Your foundation needs defined roles, business goals arranged properly, and governance models designed for AI's unique needs rather than traditional approaches.
Strict data collection and quality standards ensure AI systems get the right inputs. The difference between structured and unstructured data substantially affects project complexity. Data profiling, validation, and automated quality checks protect accuracy and reliability.
A scalable data architecture provides the infrastructure backbone that powers AI initiatives. Organizations must design flexible pipelines to handle up-to-the-minute workloads while maintaining data versioning and reproducibility, whether they choose data lakes, lakehouses, or hybrid approaches.
Detailed data preparation addresses both performance optimization and compliance requirements. Feature engineering boosts model accuracy, while anonymization techniques protect privacy. Bias detection prevents discriminatory outcomes, and well-designed retention policies balance operational needs with regulatory requirements.
Raw data transformation to AI-ready assets presents challenges. Companies that become skilled at this process gain substantial competitive advantages. As AI alters the map of industries, organizations with strong data foundations will without doubt pull ahead of competitors who struggle with fragmented approaches.
Note that effective data strategy isn't just a technical exercise—it represents a fundamental business capability that drives innovation while managing risk. Your organization should establish clear governance, maintain relentless focus on quality, build expandable infrastructure, and prepare data with both performance and compliance in mind. These steps help ensure AI initiatives deliver measurable value instead of becoming expensive experiments with limited returns.
FAQs
Q1. What are the key components of an AI-driven data strategy? An effective AI-driven data strategy includes establishing a strong data governance foundation, implementing rigorous data collection and quality standards, designing scalable data architecture, and preparing data for AI model training while ensuring compliance. It's crucial to align the strategy with business objectives and continuously monitor and improve data processes.
Q2. How does AI data governance differ from traditional data governance? AI data governance requires a more dynamic and continuous approach compared to traditional governance. It focuses on ethical considerations, transparency, and auditable processes specific to AI systems. AI governance also demands ongoing monitoring of model performance and decision-making as systems evolve, which isn't typically part of traditional frameworks.
Q3. What are the best practices for data preparation in AI projects? Best practices for AI data preparation include feature engineering to optimize model performance, data labeling for supervised learning, and implementing anonymization techniques to protect privacy. It's also crucial to conduct bias detection and fairness audits on training data, and establish clear retention and deletion policies that balance AI training needs with regulatory compliance.
Q4. How can organizations ensure data quality for AI systems? Organizations can ensure data quality for AI systems by implementing automated data quality checks, conducting regular data profiling and validation, and establishing robust metadata management and data lineage tracking. It's also important to use AI-powered tools for anomaly detection and to maintain clear documentation of data sources and transformations.
Q5. What are the considerations when choosing between cloud and on-premise storage for AI data? When deciding between cloud and on-premise storage for AI data, organizations should consider factors such as scalability, cost, security requirements, and the need for customization. Cloud storage offers flexibility and easy access to emerging AI technologies, while on-premise solutions provide greater control and can be preferable for highly sensitive data. Many organizations opt for a hybrid approach to balance these considerations.


